Connecting to Amazon Redshift
1. To add a new connection, navigate to the File tab and click on Edit Connections, or press [⌘ + O] | [Ctrl + O].
2. In the dialog box, click the Add icon (➕) next to the Connections header and select Redshift.
3. To finish creating a connection, enter valid data in the fields of the New connection dialog.
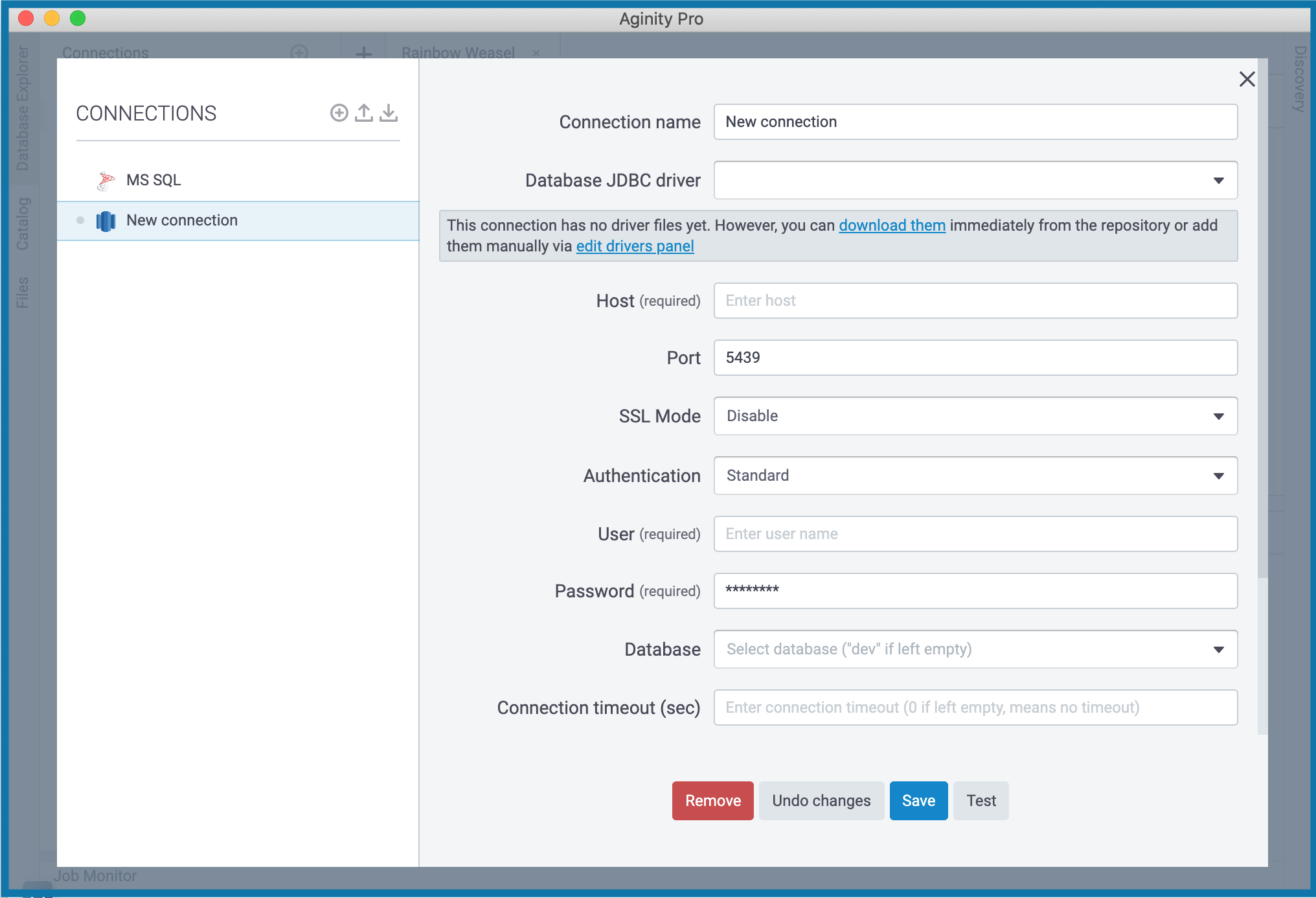
- Connection name – Replace the default New Connection with a meaningful value.
- Database JDBC DRIVER – Specify user drivers for the data source, or click the 'download them' link below this field settings area. For detailed instructions on setting up drivers, see Add a user driver to an existing connection.
- Host – Enter the hostname from your Redshift cluster settings.
- Port – The default value is
- SSL Mode – You have several options to set up the SSL mode:
- Disable – when SSL is disabled, the connection is not encrypted.
- Prefer – SSL is going to be used if the server supports it.
- Allow – SSL is going to be used if the server requires it.
- Require – SSL is always required.
- Authentication – The default value is Standard. You can configure this option with advanced settings.
- User and Password – Enter your Redshift credentials.
- Database – Select the database to connect to in your Redshift cluster.
- Connection timeout (sec) – Specify the value to tell the session when to disconnect.
- Advanced Properties – Supply additional JDBC parameters if needed.
- Click Test to ensure that the connection to the data source is successful.
- Click Save. A newly created connection will be displayed in your Database Explore panel just right under the Connections header.
🔎 NOTE: If you need more advanced information on how to set up a Redshift connection, please, contact us through support@coginiti.co
🔎 TIP: Here is also a link with recommendations from Amazon
🔎 NOTE: If you need to connect to Amazon RDS or Amazon Aurora, please, select Postgres connection type.
Amazon Redshift Data Share
We are excited to support the Redshift Data Share feature. This capability enables cross-database and cross-cluster data sharing. You can securely and easily share live data between your Redshift clusters. Amazon Redshift Data Share provides granular, instant, and high-performance data access within clusters without the need to copy or move it manually. With live access to all your data, you'll always see only up-to-date, consistent information updated in the data warehouse.
- On the PRODUCER CLUSTER, for each database, you'll be able to create data share using third-party syntax; see the DATASHARE container object with leaves for any added objects included both shared table objects and also remote consumers.
- On the CONSUMER CLUSTER, you'll be able to create a database over shared data using third-party syntax; see remote data shares at the cluster level, with leaves for the data objects.
🔎 TIP: Check Amazon's article about data sharing for more information
Redshift Stored Procedure and Function Parser
We learn to recognize the routine-like code as a single statement. Starting from Coginiti v22.03, running a script with multiple procedures or triggers (or any entity with a semicolon inside) is possible in all supported modes: at cursor, in a sequence, and as batch. Even if ‘$’ or ‘$$’ is present as part of the entity text, you don’t need to switch parameter parsing off. Moreover, you can specify parameters or session variables inside the statement.
Amazon Redshift ML
Amazon also released a unique feature - Redshift ML. With it, you can easily create, train, and deploy machine learning models using SQL commands. Coginiti also supports this functionality.

- You can now see available ML models straight from the database object tree
- Right-click on the proper objects to invoke the Show Model action and check the model's details in the output panel
🔎 TIP: Check Amazon's article about Redshift ML for details