The Bulk Load Wizard is a tool to help you take a local data file, upload it to cloud object storage, and then load the data to a table.
🔎 NOTE: Coginiti currently supports bulk uploading to Amazon Redshift and Snowflake. Coginiti will be adding support for other database platforms in future releases.
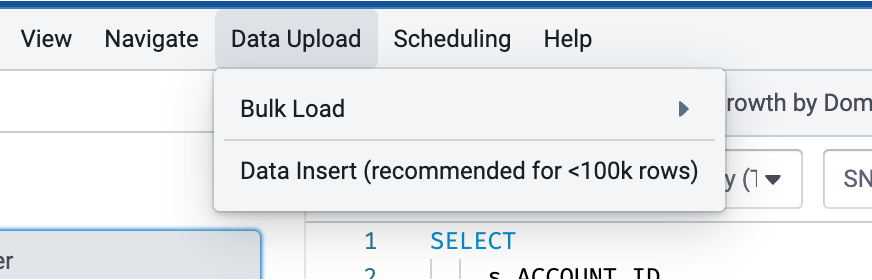
To start the data import wizard go to the [Data Upload] menu as shown below.
When you start the wizard you will be presented with a six-step process in which to identify a file to upload, describe the behavior you want and then perform the load to a table.
Choosing Connection and File
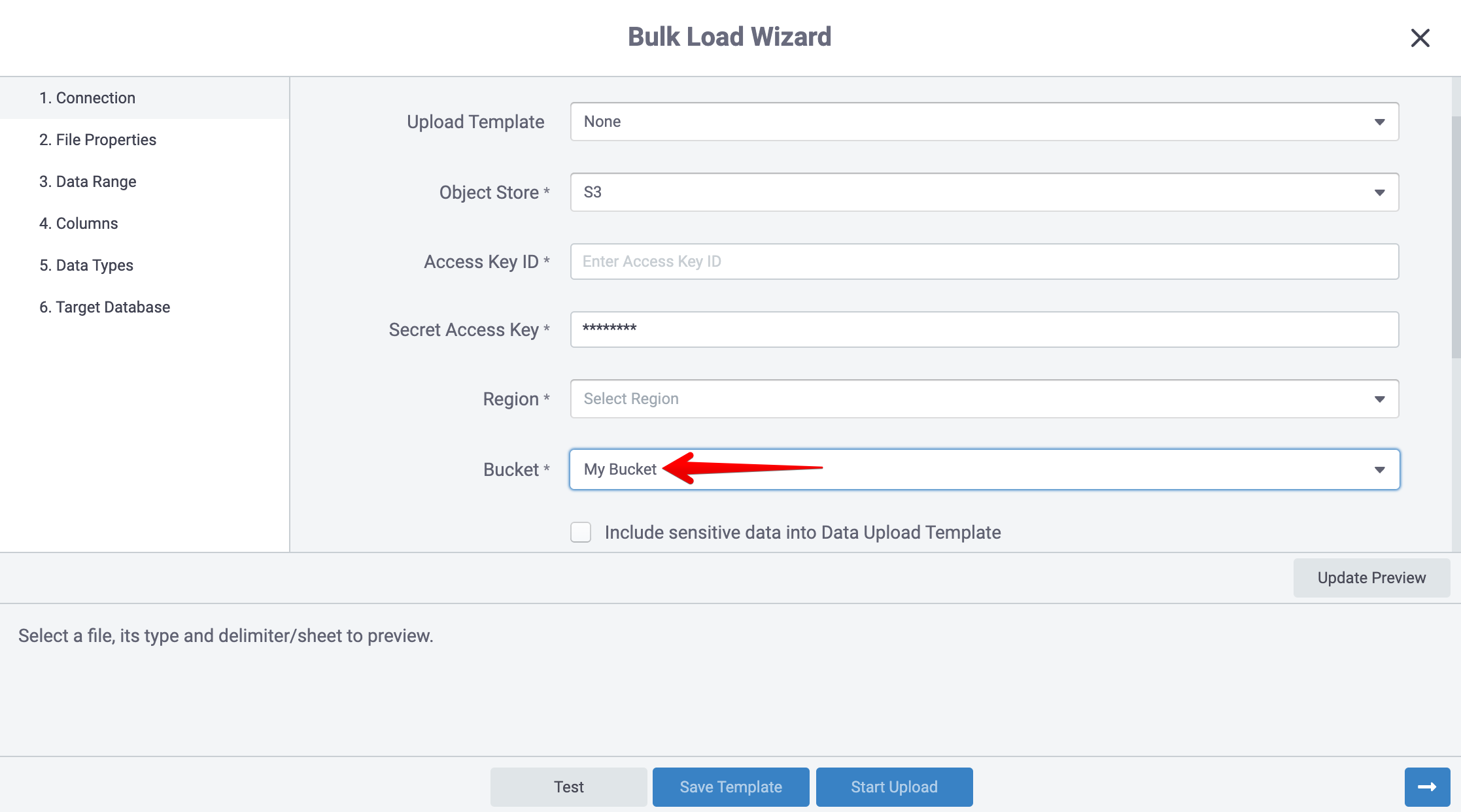
In Step ‘1. Connection’ you will pick a database connection where you will upload data to.
When working with Amazon Redshift or Snowflake the file you upload will first be moved to a S3 bucket of your choosing prior to being loaded into a Redshift table. You must provide the following items.
- Object Store
- Your Access Key
- Your Secret Key
- The Region Endpoint
- Bucket
🔎 NOTE: Below is a list of actions supported by Amazon S3 that a user must have permission to perform a data load:
List:
ListAllMyBuckets
ListBucket
ListBucketMultipartUploads
ListMultipartUploadParts
Read:
GetBucketAcl
GetBucketLocation
GetObject
Write:
DeleteObject
PutObject
More about Policies and Permissions in Amazon S3 please find here.
🔎 NOTE: If a user has access to a certain bucket only, the application will show the error 'Fetch external file system details error'. In this case, please enter a bucket name manually:
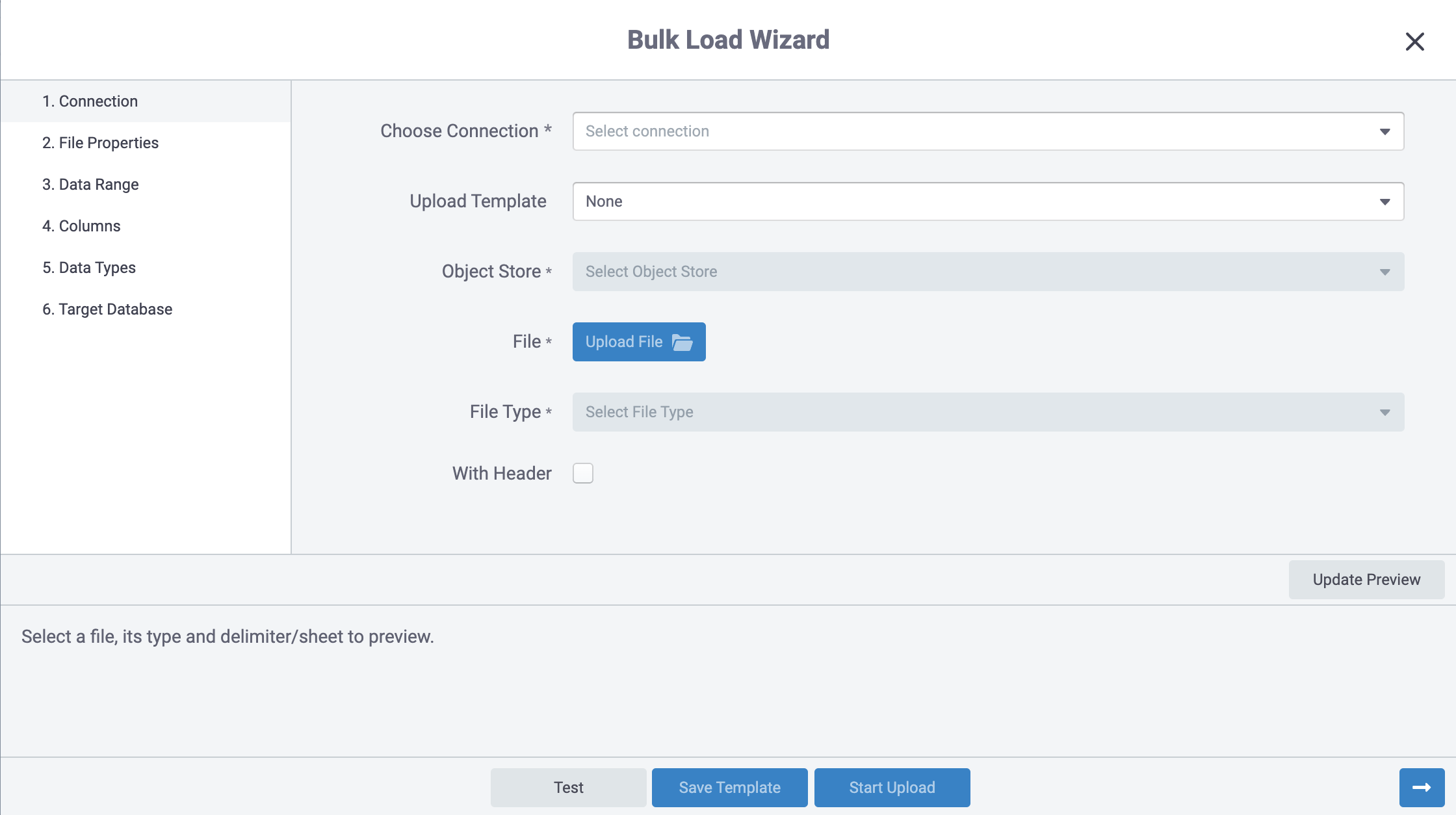
The second section lets you control the behavior of the file you upload to S3.
- Add a local file, either CSV or Excel, using the [Add File] button.
- Confirm the file type.
- For CSV files, choose a delimiter used to separate fields in the file.
For Excel files, choose the sheet with data to be uploaded. - If you click the [With header] check box the parser will assume the first row in the file is a header if not it will treat the first row as a data row.
- You can click Update preview to show the first few rows in the file.
🔎 NOTE: Also you can use the Data Upload Template by clicking on the drop-down [Upload Template]. See Data Upload Template documentation.
Setting File Properties
- If you select the checkbox labeled [Leave the intermediate file on the cloud after importing data] you will leave a version of the file on S3 (Azure Blob Storage is also an option).
- You can enter a filename of your choice for the file.
- If you want the file compressed in S3 you can choose from NONE, ZIP or GZIP options.
- You can control file behavior if the file already exists. You can either overwrite or abort the process.
🔎 NOTE: If you need information about check-box [Include sensitive Data into Upload Template] see the Data Upload Template documentation
🔎 NOTE: Please refer to the AWS Bucket Naming conventions article for proper naming standards.
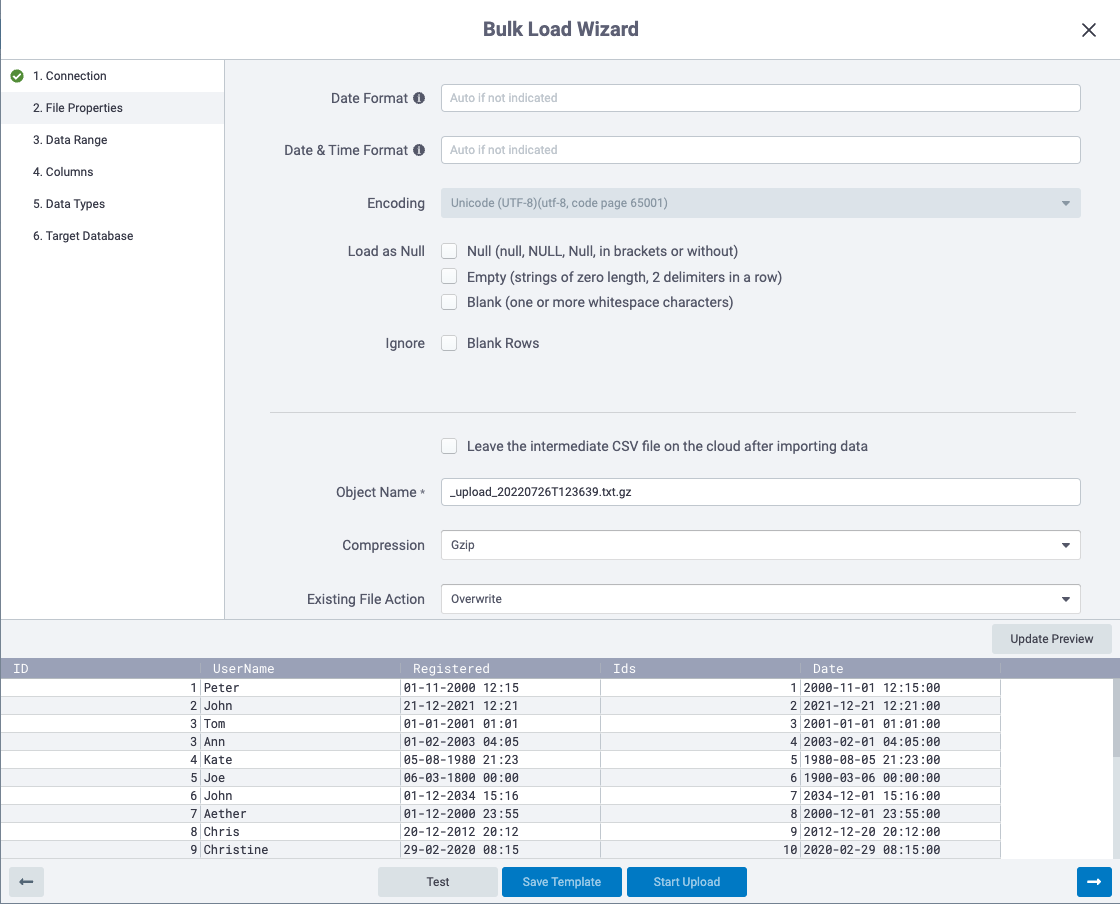
Setting Data Range
In Step ‘3. Data Range’ you can choose a numeric limiter for both the number of columns you want to parse and then the number of rows to load. This step is valuable if you have very wide and/or very deep files and want to work with fewer columns or rows.
🔎 NOTE: It is helpful with very large files to load the first 100 rows to ensure everything works well versus letting it run for an hour only to find out it didn’t work.
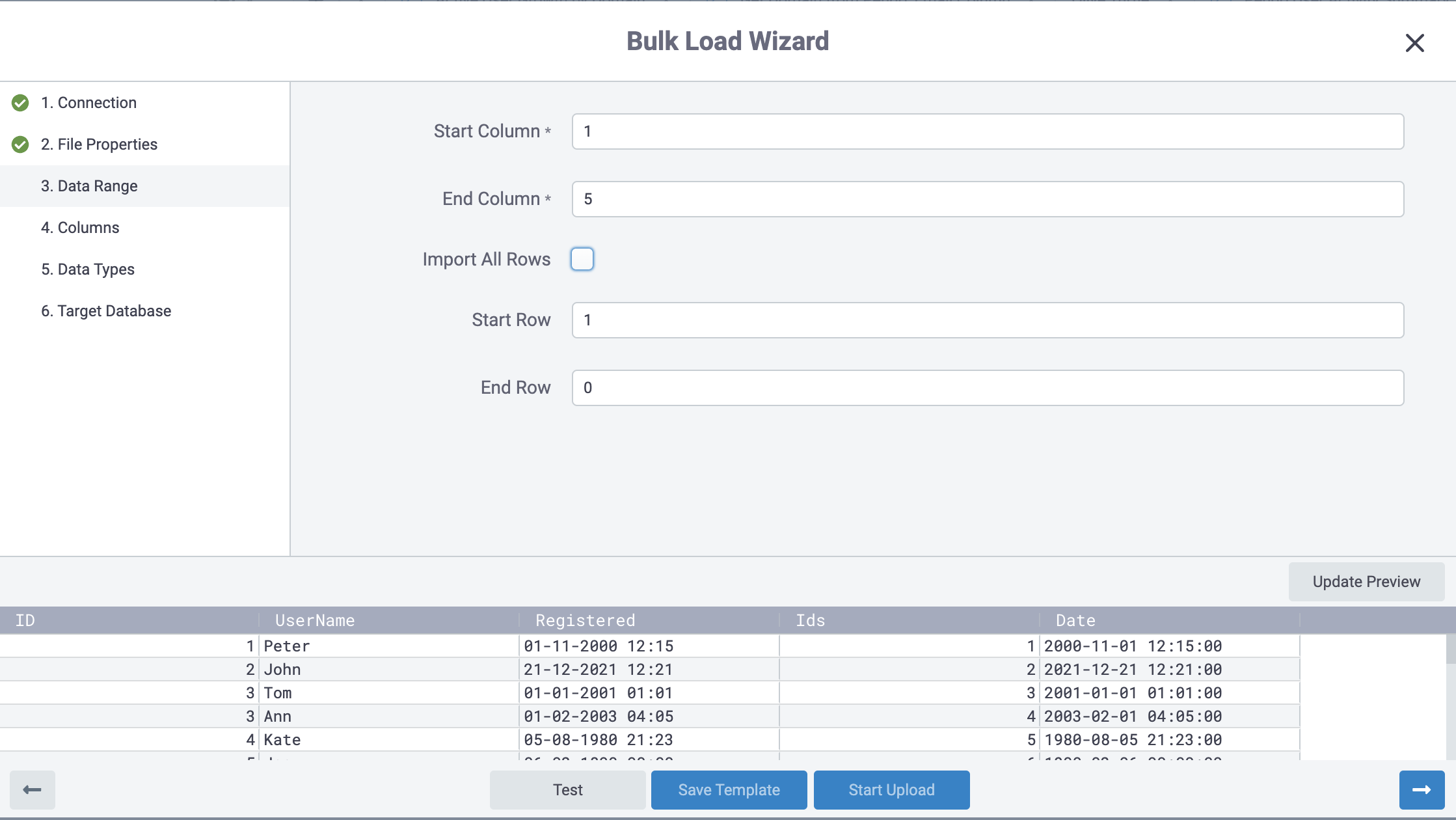
Choosing Columns
In Step ‘4. Columns’ you can select individual columns. Let’s say you have 200 columns and you know you only want the first 10, in Step 3 you can choose columns 1 to 10 and in Step 4 you can better preview and determine the order of the columns you want to load.
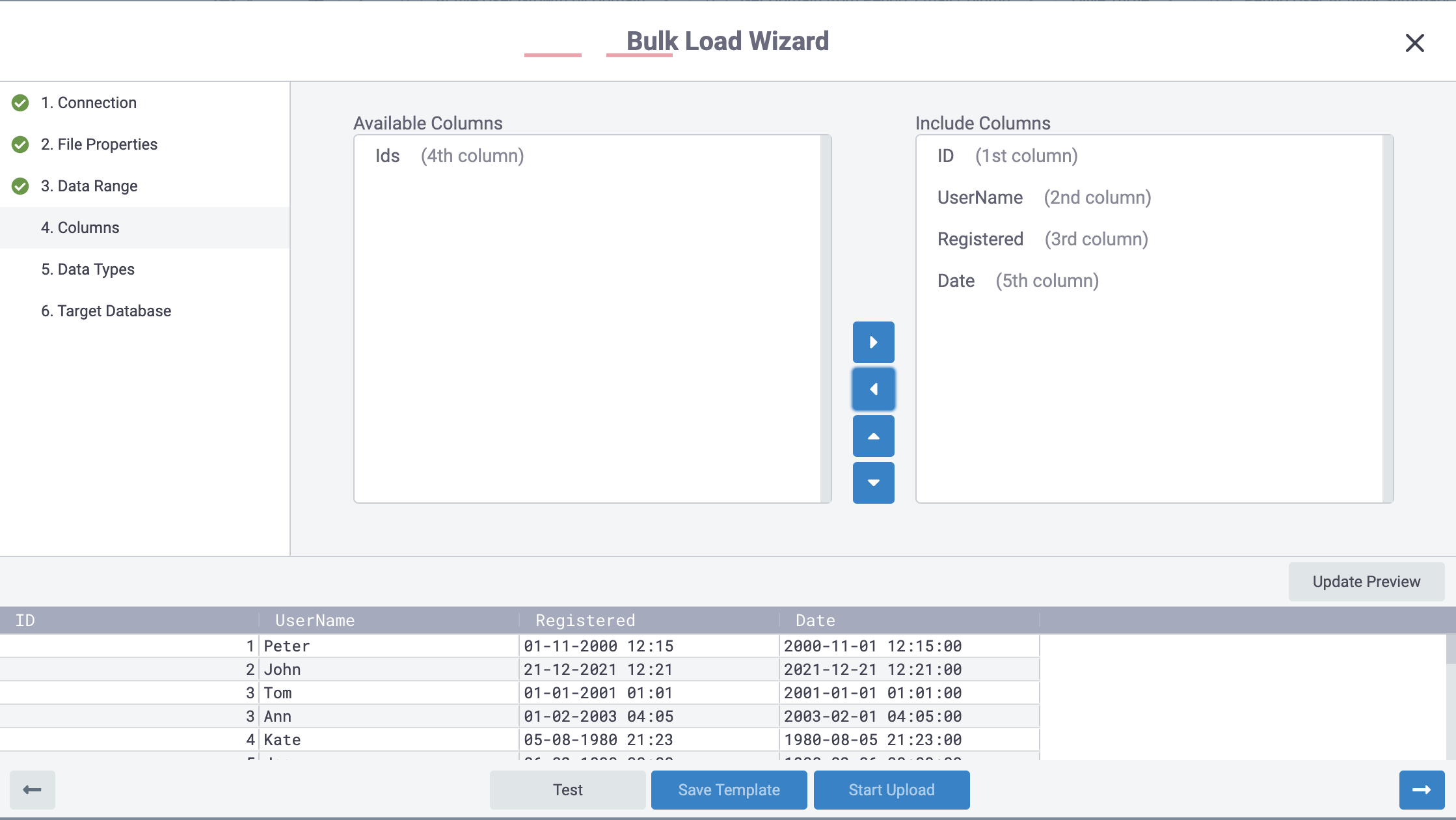
Configuring Output Columns
In Step ‘5. Data Types’ you can control column data type and nullability.
🔎 NOTE: Also you can edit the name of the chosen column.
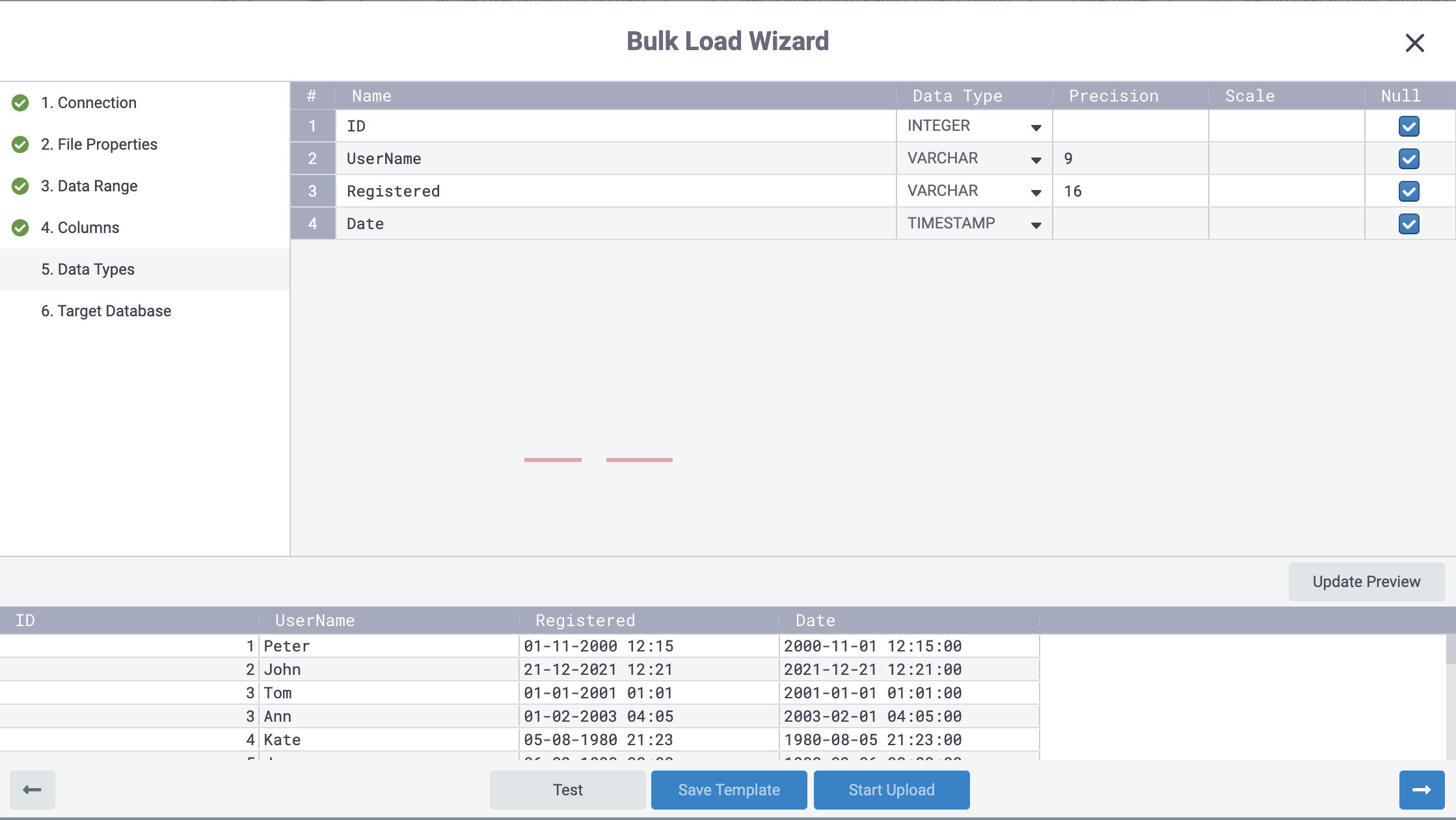
Setting Output Details and Loads
In Step ‘6. Target Database’ you will supply the database you’ll load to, schema, table name, and other behaviors that will be followed during a load execution.
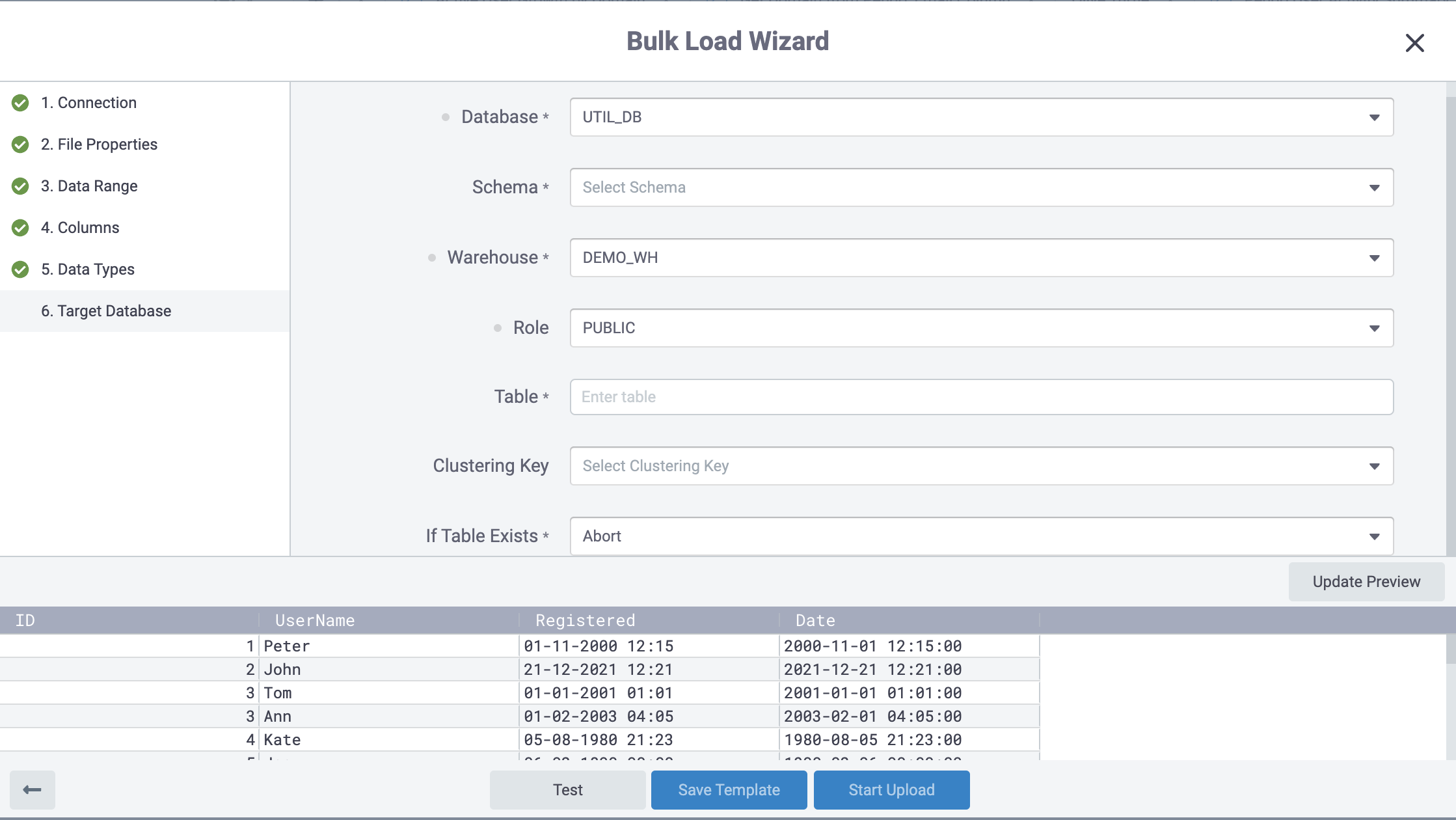
When addicting data is finished, need to click Start Upload for uploading data to the table.
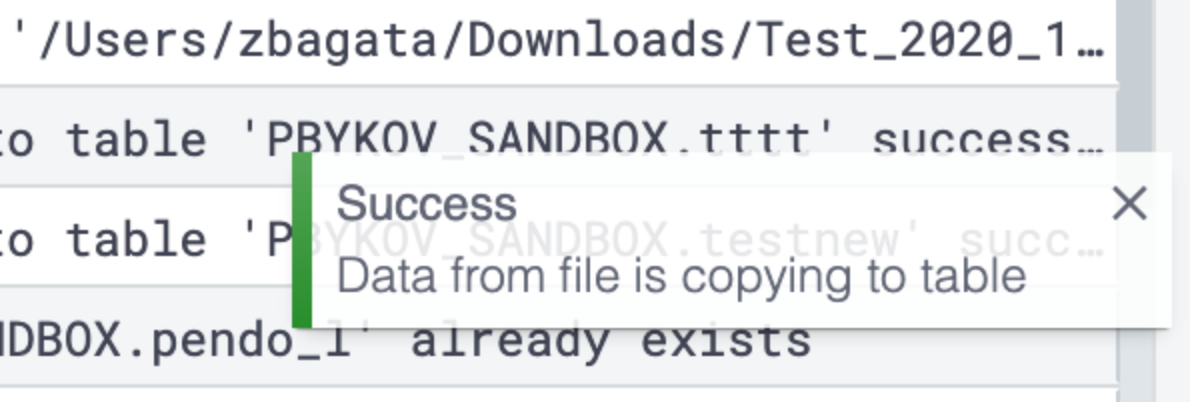
In the left corner, you can see status about success or failure for the start of the insert process; and in some time you will see a second message about success or failure for the result of the data insert.